Homograph Phishing Attacks - When User Awareness Is Not Enough

June 02, 2022

Microsoft Office vulnerable to homograph attacks
Homograph (also known as homoglyph) phishing attacks are based on the idea of using similar characters to pretend to be another site. While most of them are easily recognizable by end-users with proper training (for example, g00gle.com), the homograph attacks based on international domain names (IDN) can be unrecognizable from the domains they are spoofing.
Most security research on IDN homograph attacks has been focused on browsers – but domain names are used by other applications, which are still vulnerable. We recently tested several other applications, and the behavior was inconsistent – some applications always display the real address, while others display an international name. But the elephant in the room was surprising - all Microsoft Office applications and versions were vulnerable to IDN homograph attacks – including Outlook, Word, Excel, OneNote, and PowerPoint.
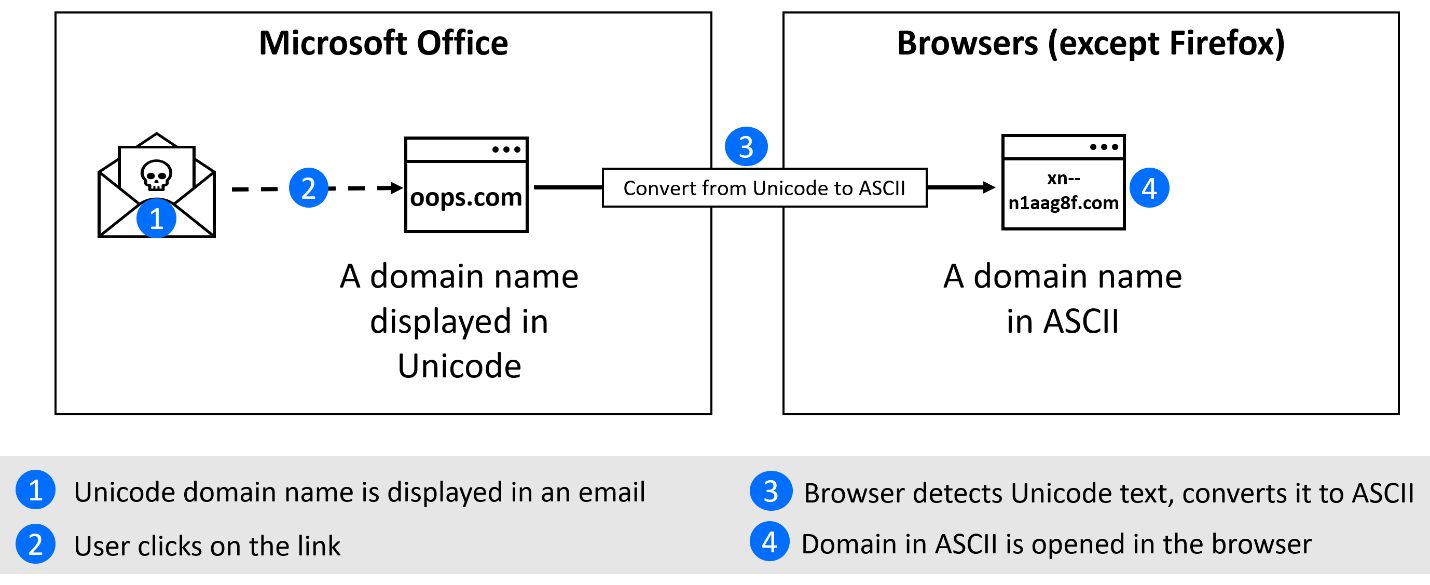
Fig 1: Example of international domain name resolution in Microsoft Office and browser
In the screenshot below (from Outlook 365), all links point to a spoofed apple.com domain. Even if a browser decides to display the real name after opening the link, the email client uses the display name in the preview pane. Users, who are trained to validate a link in an email client before they click it, will be susceptible to click on it because it has not yet been translated to a real domain name in their browser. The real domain name would only be seen after the page has started to open. The website that opens even has a valid security certificate and is fully controlled by a threat actor.
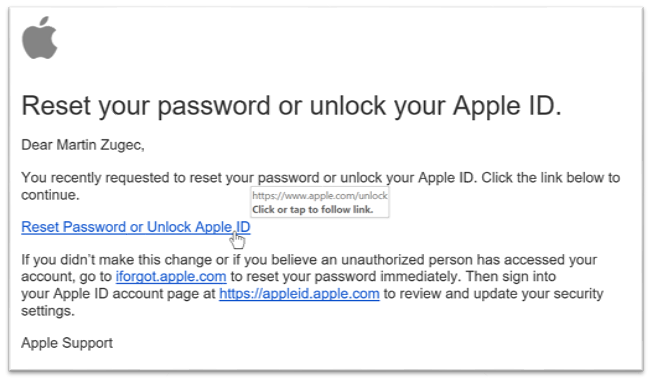
Fig 2: Malicious URL as seen in Outlook 365
We reported this issue to Microsoft in October 2021 and the Microsoft Security Response Center confirmed our findings as valid. As of June 2nd 2022, it is unclear if or when will Microsoft fix this issue.
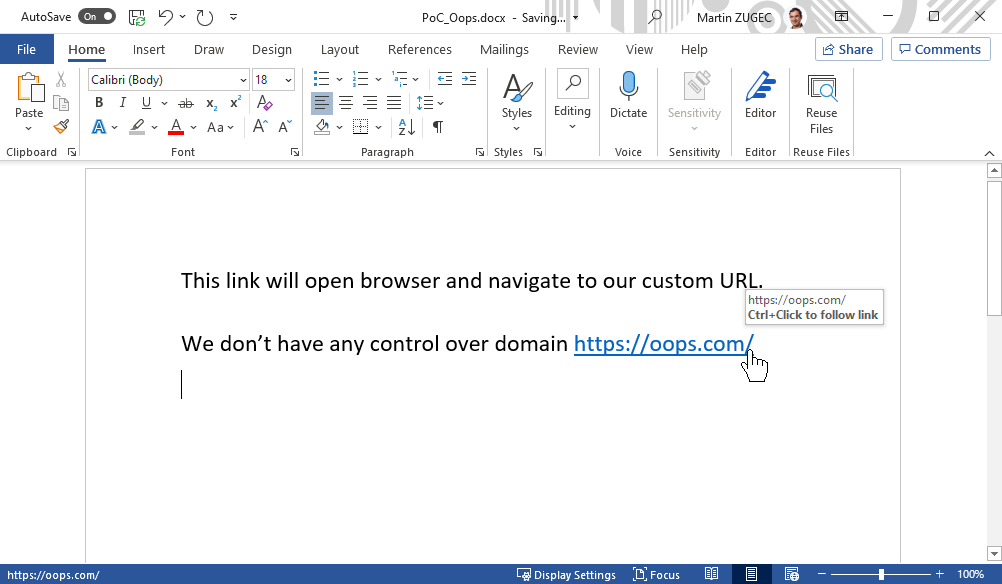
Fig 3: Microsoft Office applications (Word, Excel, PowerPoint, and others) preview homograph links indistinguishable from the spoofed domain. The actual domain linked in this document is xn--n1aag8f.com.
The good news is that homograph attacks most likely are not going to become mainstream – they are not easy to set up or maintain. However, they are a dangerous and effective tool used for targeted campaigns by APTs (or advanced persistent threats) and high-level adversaries such as Big Game Hunting by Ransomware-as-a-Service groups– whether targeting specific high-value companies (whale phishing) or high-value themes (for example popular cryptocurrency exchanges).
History of homograph vulnerabilities
The internet was not created by a single inventor. Instead, it was developed by many different people, working on diverse standards and technologies. These Internet pioneers had two things in common – they used the Latin alphabet, and their common language was English. The internet was not only invented by English speakers – it was designed for the English language.
I grew up in Czechoslovakia – a country that uses two slightly different Latin alphabets, one for the western part of the country (Czechia) and one for the eastern part (Slovakia). Head 60 miles (100 km) further east from my birthplace and you will encounter not only a different language, but also the very different Cyrillic alphabet. In Europe, you can miss a turn and end up in a village with a completely different language!
After the end of the Cold War, access to modern technologies finally opened to those of us in Czechoslovakia and the other countries in Eastern Europe. We were eager to use these new technologies but found that they were designed for the Western world. We needed to find a way to make them fit our own languages. Arabic speakers started using numbers to substitute for certain letters not found in the English Latin-based alphabet. Slavic speakers dropped diacritics (those special characters above letters like “ž”). I stopped using my real name “Žugec” and switched to the simpler “Zugec” many years ago. In fact, this is the first time in several years that I have written my name the proper way. We accepted the design limitations of the original internet (without thinking about them) and moved on.
Decades later, a new mechanism called Internationalizing Domain Names in Applications (IDNA) was introduced. This new standard allowed for the use of non-standard characters in domain names. I could finally get a domain žugec.sk – but I didn’t need it or want it. It was a solution looking for a problem.
International domain names rely on Punycode. Punycode can represent Unicode characters using the limited ASCII character set - for example, my localized domain žugec.sk is actually a domain xn--ugec-kbb.sk. You can think about them as a display name (žugec.sk) and the real name (xn--ugec-kbb.sk).
Abuse of international domain names
Homograph phishing attacks are based on the idea of using similar characters to pretend to be another site. The most basic homograph attack is substituting “o” for “0” (for example, g00gle.com). Even if it’s simple, this is still quite a successful method.
But with the introduction of international domain names, security researchers and threat actors noticed that letters in different alphabets can look very similar. Often there are only minor differences – my language has not only the letter “a”, but also the letters “á” and “ä”. It’s relatively easy to miss this in domains like “microsofť.com” (the last letter is “Ť”, not “T”). Other differences are even more subtle, or completely invisible – for example, at first glance, letter “a” is almost identical in Latin (U+0061) and Cyrillic (U+0430) alphabets, as shown in Fig 4 below, but computers actually interpret them as two unique letters.

Fig 4: Comparing Latin and Cyrillic versions of letter “a“, source Wikipedia
Characters that look similar are known as homographs (or homoglyphs) and they exist in all three major European alphabets (Latin, Cyrillic, and Greek). Homograph attacks abuse similarities between these characters – and the fact that Unicode treats them as separate entities instead of unifying them under the same code number. For humans, “a” and “a” look the same, but computers see them as a completely different letter.

Fig 5: Venn diagram of overlapping letters in European alphabets (Latin, Greek, and Cyrillic), source Wikipedia
Threat actors create international domain names that resemble a target domain name when planning a homograph attack. This domain name can be based on the same script – for example, https://www.bițdefender.com uses the Latin-based Romanian alphabet with “t“ replaced by the similar character with the addition of a diacritic “ț“) and all the other characters from the Latin alphabet.
They can also use a non-Latin script – for example, https://оорѕ.com/ is crafted using letters from the Cyrillic alphabet, but it looks familiar to Latin readers. Under certain conditions, homographs are undetectable by a regular end user. Can you tell which one is right, “аpple.com“ or “applе.com“?
The answer is that both are wrong: the first borrows an “a“ and the second borrows an “e“ from the Cyrillic alphabet.
Homograph attacks are not a new concept. They were first described as far back as 2001 (The Homograph Attack) and these types of attacks make regular comebacks in the security community – because even after almost 20 years, this problem has not been fully solved yet. Security researcher DobbyWanKenobi recently discovered a method for spoofing contact information in Outlook.
Domain registrars and browsers
Over the years, there have been multiple attempts to solve this problem. Today, we rely on a combination of domain registration vetting and awareness built into client applications as the two most common methods to prevent the risk of these attacks.
The first approach is focused on the domain registration process. For example, domain names cannot mix different languages / scripts, which makes these attacks harder to execute. You cannot take a domain name like amazon.com and substitute only one of the letters with a letter from the Cyrillic alphabet. When a Unicode character is detected in the requested domain name during registration, you are asked to specify the language – and all letters must come from that alphabet.
If your target domain consists of a combination of letters "ј ѕ і а е о р с у х s" (the letter “s” does not exist in the Russian/Ukrainian alphabet, but it exists in Macedonian), you can register a spoof domain that is unrecognizable from the original domain in the Latin-based alphabet (for example, look at domain https://оорѕ.com/ registered by Bitdefender, which is based on Cyrillic script and Macedonian alphabet). If your target domain contains other letters that are not present in Cyrillic alphabets, you can use one of the Latin-based languages as a base and craft an imperfect imposter – for example amazoń.com (using the letter ń from the Polish alphabet).
The second approach relies on the client software handling of IDN domain names – this typically refers to browsers, but other software like Slack or Microsoft Teams also have special handling for international domain names. When client software encounters an international domain name (always prefixed by xn--), it can decide to show the real name in the address bar (https://xn--ugec-kbb.sk) or show the display name (https://žugec.com). In other words – it is up to the client software to decide how to deal with these potentially malicious sites. And the response is not always the same. Most browsers will display the real name (in ASCII format) when the site is suspicious. Firefox (even the latest version 93) shows the display name (the reasoning from developers is here).
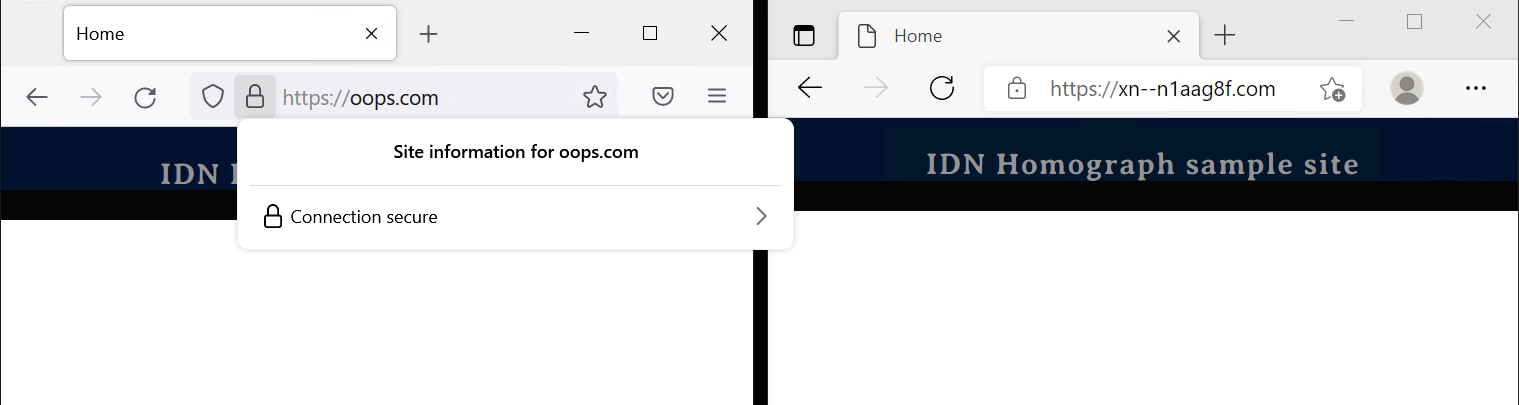
Fig 6: Same site https://оорѕ.com/ as seen in Firefox 93.0 (left) and Microsoft Edge (right)
Notice that the site in the previous screenshot has a valid security certificate. Because the real domain is https://xn--n1aag8f.com, all that is needed is a certificate for that site, easily obtainable from Let’s Encrypt. Seeing the real domain name and a symbol of encrypted communication is more than enough for most end users to proceed. In Bitdefender Labs telemetry data, we see that almost 10% of homograph domains use HTTPS. The combination of certificates and HTTPS further improves end user trust in accessing a malicious site. To see a good example of a spoofed site, read our report about homograph phishing attack with valid TLS certificate from 2019.
IDN homograph attacks are not common – they require custom domain registration, and most browsers don’t use the display name anymore (Unicode), instead they will use the real name (ASCII). While this makes it impractical for most attackers, it is a viable option for highly motivated threat actors.
Our recommendations
- Cover the possibility of homograph attacks in your user awareness training. ”Check the URL and then the lock icon“ might not be good enough, especially for employees at higher risk for spear phishing.
- Instead of solely relying on users, implement an endpoint security solution that detects and blocks malicious websites. Bitdefender Network Attack Defense (a feature of Bitdefender's endpoint security solution) provides seamless protection for end-users from this and many other similar threats.
- Use IP and URL reputation services for all your devices. As a simple rule, if the URL begins with
xn--, the site is suspicious. International domain names are rarely used for non-malicious activities, except for a few countries. Integrate Bitdefender Threat Intelligence (TI) with your existing security infrastructure to deliver up-to-date, contextual intelligence on URLs, IPs, domains, and certificates. - Use multi-factor authentication to prevent credential harvesting.
- Keep your browser (and other productivity tools) up to date. The default behavior of your applications impacts your ability to detect homograph attacks.
- Consider the possibility of homograph attacks in the supply chain. How much damage can be done by spoofing the domain identities of your critical suppliers, customers, or partners?
- Register all domains that could be associated with your company. Because IDNs are limited to a single character set, combinations are limited. During our research, we noticed few companies proactively register all potential spoofing domains.
Summary
We review data in our telemetry every month to gain more insights into the homograph attack threat landscape. We see a clear tendency to target financial operations, with a primary focus on cryptocurrency markets. For more details on top spoofed domains and categories, be sure to read our monthly Bitdefender Threat Debrief.
Additional Resource:
Read about another vulnerability found within Microsoft Office - CVE-2022-30190 (Follina).
We would like to thank Bitdefenders Alin Damian and Horia Zegheru (sorted alphabetically) for their help with putting this report together.

tags
Author
Martin is technical solutions director at Bitdefender. He is a passionate blogger and speaker, focusing on enterprise IT for over two decades. He loves travel, lived in Europe, Middle East and now residing in Florida.
View all postsRight now Top posts

: From Friend to Foe, and Back Again")


FOLLOW US ON SOCIAL MEDIA
SUBSCRIBE TO OUR NEWSLETTER
Don’t miss out on exclusive content and exciting announcements!
You might also like
")





Bookmarks
